Intel AES-NI使用入门
文章目录
Notice
本文首发于安全客,欢迎各位捧场:链接
AESNI是Intel开发的一种x64架构的SIMD指令集,专门为AES加密算法提供硬件加速,对SIMD有一定了解的人基本都知道AESNI的存在。但由于AES本身的不对称结构,以及AESNI的特殊设计,在实际使用AESNI时,还是有很多细节和理论知识需要了解,才能写出正确的代码。以N1CTF 2021中的easyRE为例,总结了一下自己对AESNI的理解,若有不对的地方敬请指正。
AES的结构
以AES128为例,其结构是10轮4x4排列置换网络,尾轮相较普通轮缺少一个MixColumns变换。
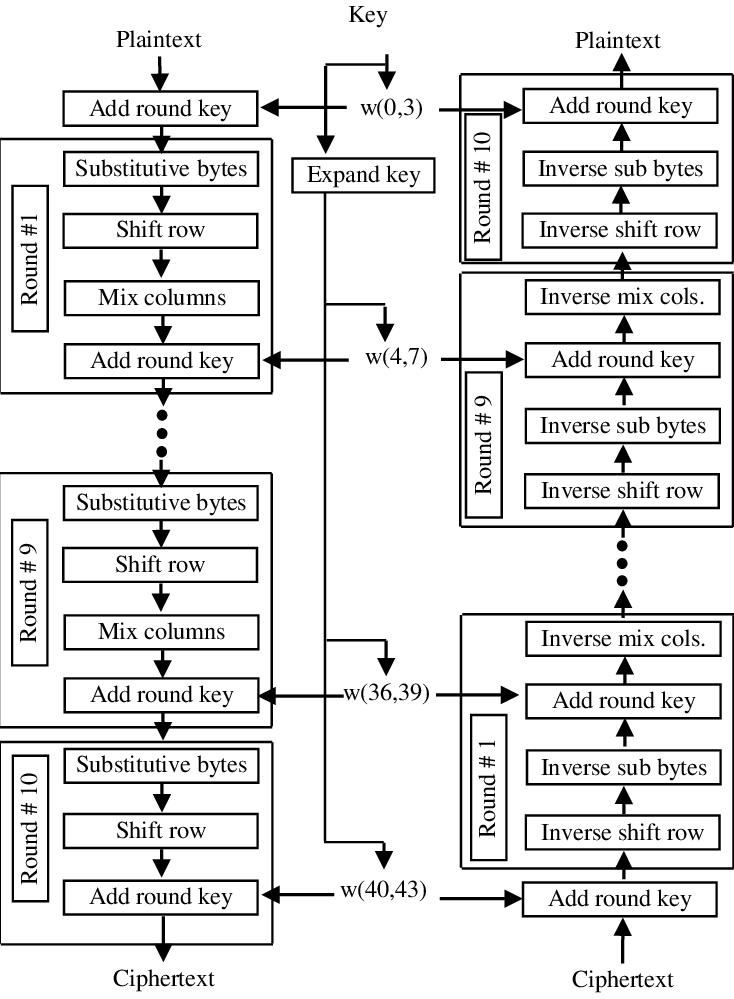
需要注意的是虽然轮数是10,但是仔细看左上角可以发现进入首轮之前还有一个AddRondKey操作,所以共有11个轮密钥。加密的开头和结尾均为AddRondKey,这种设计叫做白化。白化的用意也容易理解,由于其它3种操作不涉及密钥,仅为固定变换,如果放在加密的开头或结尾,任何人都可以直接进行逆变换解除之,这些操作的存在不能提升算法的安全性,因此没有意义。
AESENC和AESENCLAST
这两条指令是AESNI中用于加密的指令,也是最容易理解的指令。任何SIMD指令都可以参考Intel® Intrinsics Guide,AESENC对输入依次进行ShiftRows,SubBytes,MixColumns,AddRoundKey操作。其中SubBytes是对字节的操作,因此可以和ShiftRows互换,与上面的图比较,可以发现AESENC恰好是上图的一个普通轮加密。
AESENCLAST对输入依次进行ShiftRows,SubBytes,AddRoundKey操作,相当于上图的尾轮加密。
第0个轮密钥异或操作可以用PXOR指令完成,因此一个完整的AES加密过程如下(pt是明文,k[x]是轮密钥,ct是密文):
| |
AES是9轮AESENC+1轮AESENCLAST这一点很容易记住,但第0个轮密钥是直接PXOR这一点很容易被忽视掉,需要多加注意。
AES的解密算法和等价解密算法
AES的不对称设计十分具有迷惑性,再仔细观察上图右侧的解密过程,可以发现解密时也是白化+9轮普通轮+1轮尾轮。
这里要注意,如果直接按照加密的逆过程来考虑,那么解密应该是先解密尾轮,再解普通轮,然而上图显然不是这样。
如果不考虑轮的划分,只看分开的4种操作的话,解密的操作恰为加密操作的逆序。但若想将一系列的操作划分成不同的轮,就有很多种划分方式。上图是最常见的划分方式,其中解密轮并不是加密轮的逆运算,这一划分方式是AES的设计中第一个违反直觉的地方。
在上图的划分中,一个解密轮包括InvShiftRows,InvSubBytes,AddRoundKey,InvMixColumns操作,尾轮同样是移除InvMixColumns操作。
AES原名Rijndael,在Rijndael最初的提案中,设计者另外给出了一种“等价解密算法”(参见5.3.3 The equivalent inverse cipher structure),在等价解密中,解密轮的AddRoundKey和InvMixColumns操作顺序互换,形成了一种和加密轮相同,AddRoundKey均在最后的对称结构(InvSubBytes和InvShiftRows本身可以互换顺序):

这一交换并非等价变换,InvMixColumns是对每一列的4个字节在GF(2^8)上乘上一个4x4矩阵,得到一个新的1x4向量,而AddRoundKey是对每个字节进行异或操作。在GF(2^8)上,异或操作即为加法运算,根据乘法分配律就可以推出,若将AddRoundKey移至InvMixColumns后,新的RoundKey应为原RoundKey乘上同样的4x4矩阵,才能保证运算结果不变。
再仔细观察解密的流程图,第0个轮密钥直接异或,最后一个轮密钥在解密的尾轮中,这两个轮密钥均不涉及InvMixcolumns的交换,因此在等价解密的过程中,除了需要将加密的轮密钥逆序外,第1~第n-1个轮密钥应先进行InvMixColumns,变换成解密用密钥。
AES加密和等价解密的轮之间具有一种奇特的对称美学,但轮密钥不同,这是AES的设计中第二个违反直觉的地方。
AESDEC,AESDECLAST和AESIMC
根据AESNI的设计白皮书,Intel同样采用了等价解密,参考Intel® Intrinsics Guide,注意AESDEC指令不是AESENC指令的逆过程,AESDECLAST同样不是AESENCLAST的逆过程。一个完整的AES解密过程如下(pt是明文,k[x]是轮密钥,ct是密文):
| |
其中k[0]和k[n]和加密密钥相同,而k’[1]~k’[n-1]是加密密钥k[1]~k[n-1]经InvMixColumns变换的结果。为此,Intel特意提供了AESIMC指令,该指令即为进行单个的InvMixColumns操作。
AESKEYGENASSIST和PCLMULQDQ
AESKEYGENASSIST用在密钥扩展中,具体的用法可以参考设计白皮书19页。
PCLMULQDQ全称Carry-Less Multiplication Quadword,是对两个GF(2^128)域上的多项式相乘。PCLMULQDQ本身并不属于AESNI指令集,但除了用于加速CRC32外,PCLMULQDQ还能计算GCM的GMAC,因此经常出现在SIMD加密算法中。Libsodium中的AES-256-GCM实现就是一个完美的示例。
AESNI的进阶用法
分离AES的4种操作
最初尝试AESNI时曾经十分不解,为什么Intel要采用等价解密,使得生成解密密钥还要额外加上AESIMC操作,后来读完了白皮书才搞懂这一精巧的设计。
白皮书第34页给出了用AESNI单独实现AES的4种操作的方法:
| |
ShiftRows可以直接用SSSE3的PSHUFB指令完成,而SubBytes则是先反向shuffle,再用0密钥进行尾轮加密,消掉尾轮的另外两种操作。MixColumns则结合加密和解密,利用尾轮的特性将MixColumns保留下来。这个神奇的拼接方式令人啧啧称奇。
上一节提到由加密密钥变换为等价解密密钥要经过AESIMC操作,但如果已知等价解密密钥,如何获得加密密钥?AESNI里没有直接的MixColumns操作,但根据上文,可以用AESDECLAST和AESENC组合产生。
而查询Intel® Intrinsics Guide,发现Skylake微架构上,AESIMC的Latency和Throughput均是AESENC的两倍,因此斗胆猜测AESIMC内部也是AESENCLAST和AESDEC的拼接。
用AESNI加速其它算法
AESNI的灵活设计使得它可以用来实现更大的排列置换网络,前文提到AES原名Rijndael,而参考Rijndael的提案,Rijndael实际上有块大小(不是密钥大小)为128,192,256的三种变种,只有128大小的Rijndael被选为AES。白皮书则给出了AESNI实现的其它Rijndael,例如Rijndael-256:
| |
Rijndael-256是8x4排列置换网络,SubBytes,AddRoundKey是字节层面变换,可以正常工作,而MixColumns是对每列的1x4向量进行变换,同样正常工作,只有ShiftRows需要利用SSE4.1的PBLENDB和SSSE3的PSHUFB调整偏移。8x4排列置换网络是4x4的两倍,因此每一轮需要两个AESENC指令,结尾同样两个AESENCLAST。这种错落有致又不失美感的代码正是计算机吸引入的地方。
国密SM4算法中的“非线性变换τ”实际上也是一个二进制域GF(2^8)上的S盒,和AES的S盒相比,只有生成多项式p不同。根据群论知识,这两个GF(2^8)是同构的(若有不对请指正),两个域上的元素可通过代数运算互相变换。Markku-Juhani O. Saarinen据此设计了利用AESNI加速的SM4实现。参见sm4ni。
N1CTF 2021 easyRe
题目位于这里,加密函数的主要逻辑是对xmm0中的明文进行一系列的加密和打乱操作:
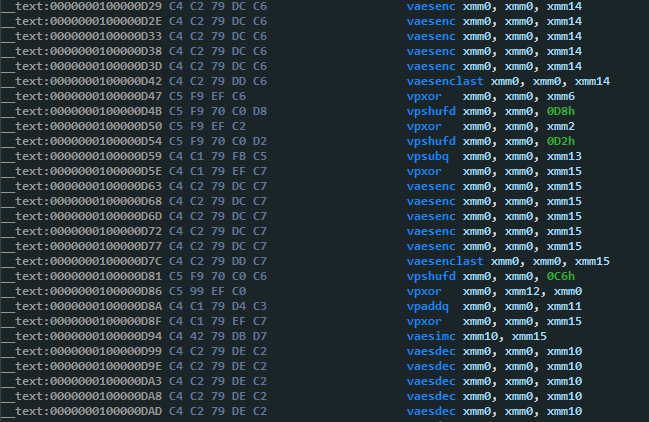
虽然程序是v开头的AVX2指令集,但只用到了xmm寄存器,可以只用SSE写出解密算法。先利用capstone解析一遍函数体,生成一个表达式树,该树的一个叶节点是输入,而该树的根节点是密文。再对该树进行变换,通过左右旋转,设法将输入节点转至最顶端根部,此时该树对应的表达式就是解密表达式。
在旋转过程中,VPXOR,VPADDQ,VPSUBQ很容易求出逆运算,VPSHUFD是对xmm0里的4个32位值重新排列,同样用VPSHUFD可以排列回去。遇到VAESENC指令时,首先将整个VAESENC+VAESENCLAST块提取出来,对中间的轮密钥VAESIMC求逆,再生成相反的解密树。注意前文提到过AES加密的第0个轮密钥是直接VPXOR异或,碰到VAESENC指令前不是VPXOR时,可以看作是异或了一个全0密钥,那么解密树的最后一条指令VAESDECLAST的轮密钥就是0。遇VAESDEC解密块时处理方法类似,但要使用前文提到的VAESDECLAST+VAESENC合成出MixColumns操作,对轮密钥进行变换。
根据表达式树写出了一个JIT,JIT产生的代码编译后运行就能得到flag:
| |
编译的时候加上-maes选项打开AESNI,会生成SSE指令集的程序,如果用-march=native再多打开一些指令集,还能自动编译出AVX2+VAES的程序,现在的编译器也是十分智能。
flag: n1ctf{Easy_AVX!}(一点都不easy)
文章作者 Nagi
上次更新 2021-11-22
许可协议 本文已投稿安全客,转载请参考安全客相关规定